Now that we know how to push down Parquet predicates the next logical step is to come up with a DSL to make writing predicates easier. The DSL would be handy for debugging, especially if it can be implemented with few additional dependencies. Running Spark just to have access to Dataset query syntax is not always convenient.
What I have in mind is something very straightforward, after all there is little else to express than predicates. It could be as simple as "SELECT * FROM '/tmp/somefile.par' WHERE ('column1'=42) || ('column2'=24)" to filter a file by a couple of columns.
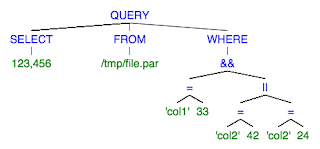

When I think about query parsers ANTLR is the default choice. Its functionality, stability, and documentation are outstanding. But the syntax I mentioned makes me think that a lighter approach could be possible. So to a significant degree this exercise will be an attempt to compare a few parser libraries in the context of very small DSLs.
I decided to start with a heterogeneous AST representation and the pseudo-SQL syntax I mentioned above. To evaluate the alternatives I am going to pay attention to:
- parser-related code size, complexity
- grammar readability
- transitive dependencies brought by the parser library
- build process changes required (e.g. maven plugins)
- tool chain, support for debugging of parser errors
Today's contender is Parboiled and its Java library in particular. The actual parser for my DSL is a reasonably small class. Syntactically, the PEG rules look quite isomorphic to how I imagine the corresponding CFG. The library provides a built-in stack that is very helpful for building AST nodes. When the stack is not enough, one can also use action variables that allow collecting results from other rules.
Parboiled wiki provides a lot of useful information and in addition there are a few nice parser examples. Parboiled is a pure Java library so there is no need for additional maven plugins. It has just a few ASM dependencies. As for debugging, I found the tracing parser very convenient.
Coding-wise, it took me some time to get used to calling "push/pop" as the last Rule in a Sequence. I also started with too many action variables but was able to covert most of them to operations on the stack.
One minor problem with Parboiled is the lack of easy means of skipping white spaces in the tokenizer. I am pretty sure my current parser can be broken by adding space characters to a query here and there. Guarding every Sequence with a white space consuming rule seems to be the only viable approach.
No comments:
Post a Comment